:quality(75)/multimodal_ai_la_gi_thumb_e334e71946.png)
Multimodal AI là gì? Cách hoạt động và ứng dụng trí tuệ nhân tạo đa phương thức
Trong thời đại dữ liệu bùng nổ, con người tiếp nhận thông tin từ nhiều nguồn như hình ảnh, âm thanh, văn bản và video cùng lúc. Multimodal AI ra đời như một bước tiến quan trọng, giúp hệ thống trí tuệ nhân tạo xử lý và kết nối các dạng dữ liệu này để hiểu ngữ cảnh toàn diện hơn. Đây được xem là nền tảng cốt lõi để AI tiến gần hơn với cách con người suy nghĩ và phản ứng trong thế giới thực.
Multimodal AI là gì?
Multimodal AI là hệ thống trí tuệ nhân tạo có khả năng xử lý nhiều loại dữ liệu khác nhau cùng lúc. Thay vì chỉ phân tích văn bản hoặc hình ảnh riêng lẻ, công nghệ này kết hợp nhiều nguồn thông tin để đưa ra kết quả chính xác hơn.

Ví dụ đơn giản, khi một người vừa nói chuyện vừa thể hiện biểu cảm khuôn mặt, Multimodal AI có thể phân tích cả nội dung lời nói, giọng điệu và hình ảnh để hiểu cảm xúc thật sự. Điều này giúp hệ thống không chỉ “đọc” thông tin mà còn “hiểu” ngữ cảnh.
Chính nhờ khả năng kết hợp và suy luận từ nhiều nguồn dữ liệu khác nhau, Multimodal AI được xem là một trong những hướng phát triển quan trọng nhất của AI thế hệ mới.
Vì sao Multimodal AI ngày càng quan trọng?
Trong hoạt động hàng ngày, doanh nghiệp tiếp nhận dữ liệu từ nhiều nguồn khác nhau như email, cuộc gọi, hình ảnh sản phẩm hay phản hồi từ khách hàng. Nếu chỉ phân tích một loại dữ liệu, hệ thống sẽ khó hiểu đầy đủ thông tin.
Multimodal AI giải quyết vấn đề này bằng cách kết hợp các nguồn dữ liệu. Nhờ đó, hệ thống có thể nhận diện cả nội dung lẫn cảm xúc, từ đó đưa ra phản hồi phù hợp hơn. Điều này đặc biệt quan trọng trong các lĩnh vực như chăm sóc khách hàng, marketing hay phân tích hành vi người dùng.

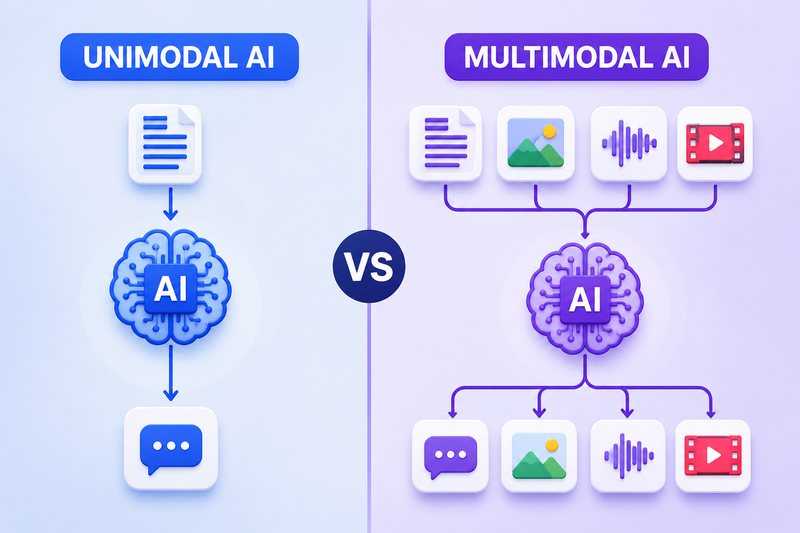
Sự khác biệt giữa Unimodal AI và Multimodal AI
Unimodal AI
Unimodal AI chỉ xử lý một loại dữ liệu duy nhất. Ví dụ, hệ thống nhận diện khuôn mặt chỉ dựa trên hình ảnh hoặc chatbot chỉ xử lý văn bản. Các ứng dụng này hoạt động tốt trong phạm vi hẹp nhưng hạn chế khi cần hiểu ngữ cảnh phức tạp.
Multimodal AI
Multimodal AI kết hợp nhiều loại dữ liệu như văn bản, hình ảnh, âm thanh và video. Nhờ đó, hệ thống có thể hiểu tình huống một cách toàn diện.
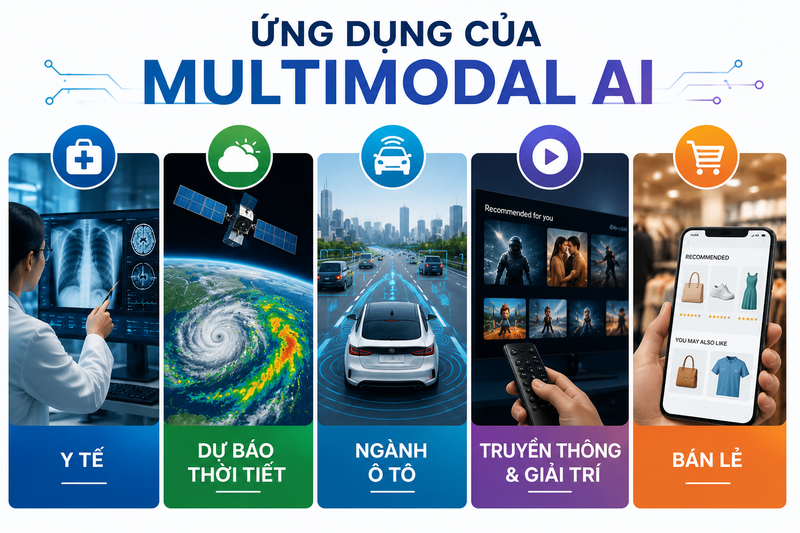
Ứng dụng của Multimodal AI bao gồm:
- Trợ lý ảo có thể nghe và nhìn.
- Xe tự lái sử dụng camera và cảm biến.
- Hệ thống chăm sóc khách hàng thông minh.
Khả năng này mở ra hướng phát triển mới cho AI, nơi máy móc có thể tương tác tự nhiên hơn với con người.
Cơ chế hoạt động của Multimodal AI
Để hiểu rõ sức mạnh của Multimodal AI, cần nhìn vào cách hệ thống này xử lý dữ liệu từ nhiều nguồn khác nhau. Không giống các mô hình AI truyền thống, Multimodal AI hoạt động theo một quy trình phức tạp, bao gồm nhiều thành phần và nhiều bước xử lý liên kết chặt chẽ với nhau.
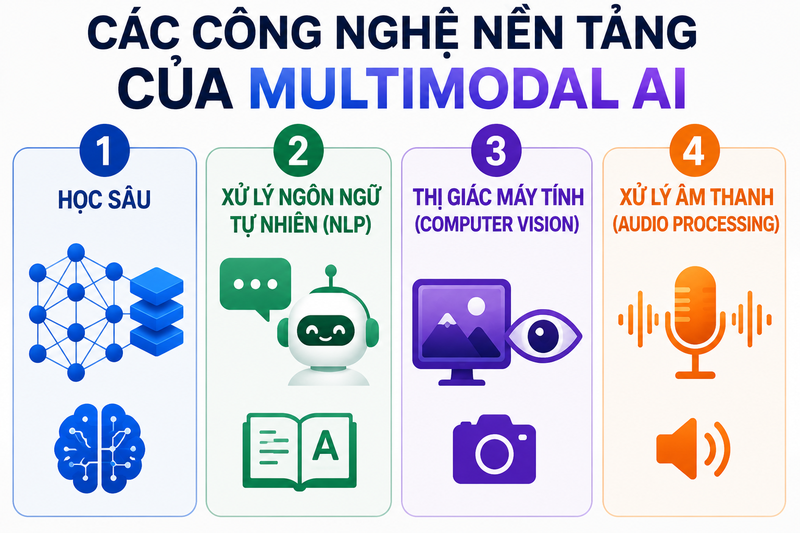
1. Các thành phần chính của Multimodal AI
Một hệ thống Multimodal AI thường được cấu tạo từ ba phần cốt lõi, mỗi phần đảm nhiệm một vai trò riêng nhưng liên kết với nhau để tạo nên khả năng “hiểu đa chiều” của AI.
Bộ phận đầu vào
Đây là nơi tiếp nhận dữ liệu từ nhiều nguồn khác nhau như văn bản, hình ảnh, âm thanh hoặc video. Mỗi loại dữ liệu không được xử lý chung ngay từ đầu mà sẽ đi qua các mô hình chuyên biệt.
Ví dụ:
- Văn bản được xử lý bởi mô hình xử lý ngôn ngữ tự nhiên
- Hình ảnh được phân tích bởi mô hình thị giác máy tính
- Âm thanh được xử lý bằng hệ thống nhận diện giọng nói
Sau khi phân tích, mỗi loại dữ liệu sẽ được chuyển thành dạng số gọi là vector đặc trưng. Đây là cách để máy tính “hiểu” nội dung dưới dạng toán học.
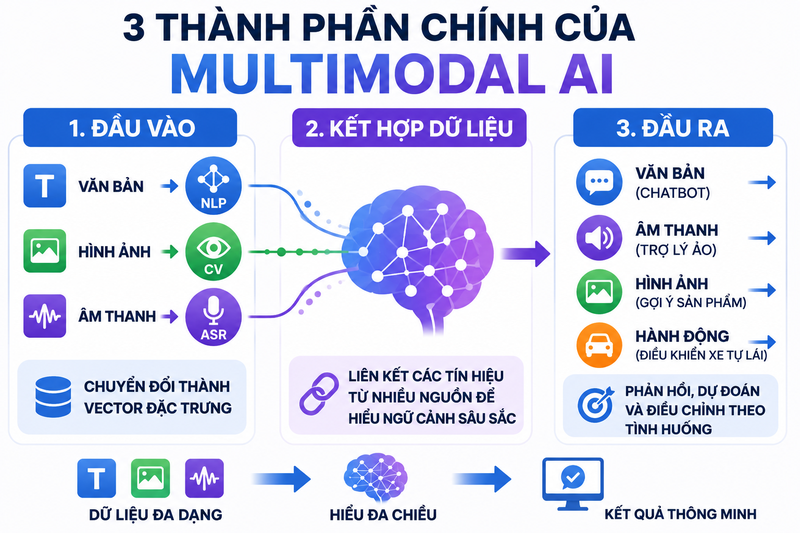
Bộ phận kết hợp dữ liệu
Đây được xem là trung tâm quan trọng nhất của Multimodal AI. Tại đây, các vector từ nhiều nguồn dữ liệu sẽ được kết nối với nhau để tạo thành một bức tranh tổng thể.
Hệ thống sẽ học cách liên kết các tín hiệu khác nhau. Ví dụ, biểu cảm khuôn mặt từ hình ảnh có thể được ghép với tông giọng từ âm thanh để xác định cảm xúc thực sự của một người.
Nhờ quá trình này, AI không còn hiểu thông tin theo từng phần rời rạc mà có thể nhận diện ngữ cảnh một cách sâu sắc hơn.
Bộ phận đầu ra
Sau khi dữ liệu đã được phân tích và kết hợp, hệ thống sẽ tạo ra kết quả phù hợp với mục tiêu sử dụng.
Kết quả có thể ở nhiều dạng khác nhau:
- Văn bản như phản hồi chatbot.
- Âm thanh như trợ lý ảo.
- Hình ảnh như gợi ý sản phẩm.
- Hành động như điều khiển trong xe tự lái.
Điểm đáng chú ý là hệ thống không chỉ phản hồi mà còn có khả năng dự đoán và điều chỉnh theo tình huống.
2. Quá trình làm việc của Multimodal AI
Để đạt được khả năng hiểu giống con người, Multimodal AI phải trải qua một quy trình xử lý dữ liệu gồm nhiều bước liên tiếp. Mỗi bước đóng vai trò quan trọng trong việc đảm bảo độ chính xác của kết quả.
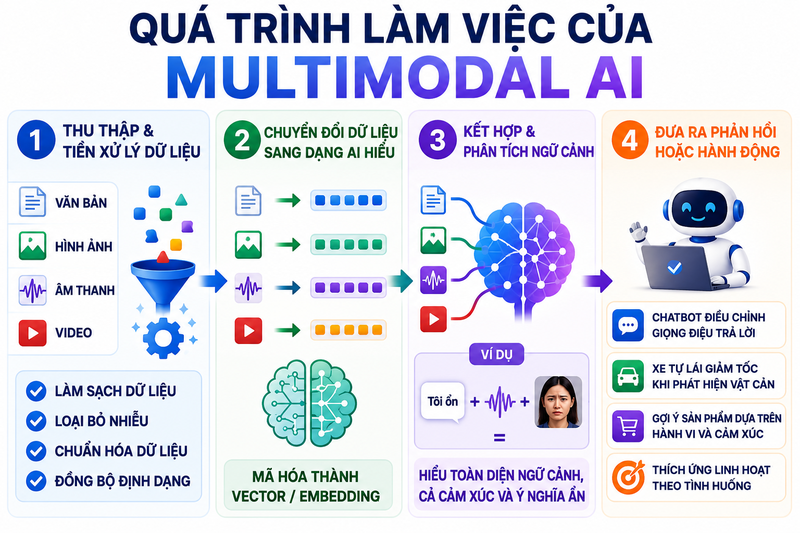
Bước 1: Thu thập và tiền xử lý dữ liệu
Hệ thống tiếp nhận dữ liệu từ nhiều nguồn khác nhau như văn bản, hình ảnh, âm thanh hoặc video. Tuy nhiên, dữ liệu thô thường chứa nhiều nhiễu hoặc thông tin không cần thiết.
Vì vậy, bước tiền xử lý sẽ thực hiện:
- Làm sạch dữ liệu văn bản.
- Loại bỏ nhiễu trong âm thanh.
- Cắt và chuẩn hóa hình ảnh.
- Đồng bộ định dạng dữ liệu.
Mục tiêu là đảm bảo tất cả dữ liệu đều đạt chất lượng tốt trước khi đưa vào phân tích.
Bước 2: Chuyển đổi dữ liệu sang dạng mà AI hiểu
Toàn bộ dữ liệu được mã hóa thành dạng số như vector hoặc embedding. Điều này có ý nghĩa rất quan trọng. Khi mọi loại dữ liệu đều được biểu diễn bằng số, hệ thống có thể so sánh và tìm ra mối liên hệ giữa chúng.
Ví dụ:
- Từ “vui” trong văn bản.
- Hình ảnh khuôn mặt cười.
- Giọng nói vui vẻ.
Tất cả đều có thể được biểu diễn bằng các vector có ý nghĩa tương đồng, từ đó AI nhận diện chúng cùng thể hiện một trạng thái cảm xúc.
Bước 3: Kết hợp và phân tích ngữ cảnh
Đây là bước quan trọng nhất trong toàn bộ quy trình. Hệ thống sẽ ghép nối dữ liệu từ nhiều nguồn để hiểu tình huống một cách toàn diện.
Ví dụ: Một khách hàng nói “Tôi ổn” nhưng giọng nói run và khuôn mặt căng thẳng. Nếu chỉ phân tích văn bản, hệ thống sẽ hiểu theo nghĩa tích cực. Tuy nhiên, khi kết hợp thêm âm thanh và hình ảnh, AI có thể nhận ra trạng thái lo lắng.
Nhờ khả năng này, Multimodal AI không chỉ hiểu nội dung mà còn hiểu cảm xúc và ý nghĩa ẩn phía sau.
Bước 4: Đưa ra phản hồi hoặc hành động phù hợp
Sau khi hoàn tất phân tích, hệ thống sẽ tạo ra kết quả phù hợp với mục tiêu sử dụng.
Một số ví dụ:
- Chatbot điều chỉnh giọng điệu trả lời khi phát hiện người dùng đang căng thẳng.
- Hệ thống xe tự lái giảm tốc khi phát hiện vật cản.
- Nền tảng thương mại điện tử gợi ý sản phẩm dựa trên hành vi và cảm xúc.
Ở bước này, AI không chỉ phản hồi mà còn có khả năng thích ứng linh hoạt theo từng tình huống cụ thể.
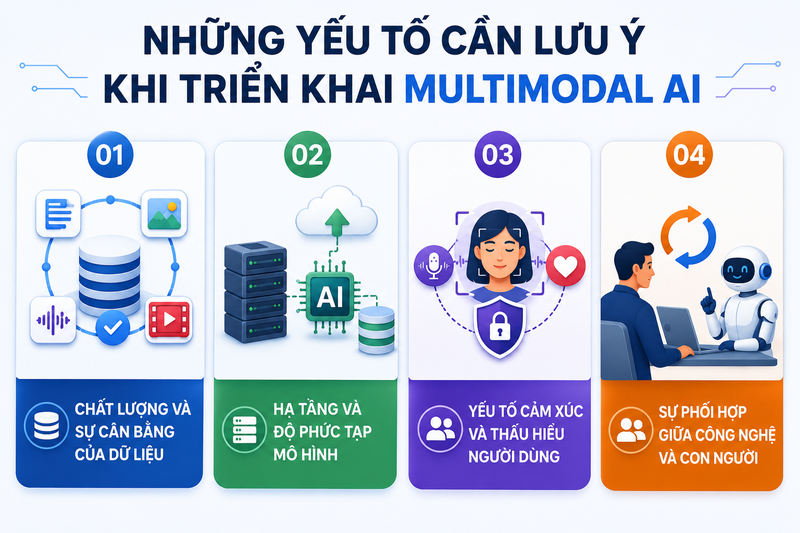
Những yếu tố cần lưu ý khi triển khai Multimodal AI
Khi ứng dụng Multimodal AI vào thực tế, doanh nghiệp không chỉ quan tâm đến mô hình mà còn cần chuẩn bị đồng bộ nhiều yếu tố nền tảng. Nếu thiếu một mắt xích quan trọng, hiệu quả xử lý dữ liệu đa phương thức sẽ bị ảnh hưởng rõ rệt.
:quality(75)/prompt_ai_3_5d6ec928a7.png)
:quality(75)/Originality_AI_thumb_99b5e5f934.jpg)
:quality(75)/pixai_2_7891819e41.png)
:quality(75)/skywork_ai_2_586597724e.png)
:quality(75)/predictive_ai_thumb_df46d6641b.png)
:quality(75)/nemoclaw_ai_la_gi_6_460994d86e.jpg)