:quality(75)/q_learning_la_gi_1_750abe680d.jpg)
Q-Learning là gì? Giải thích nguyên lý hoạt động Q-Learning và ứng dụng trong thực tế
“Q-Learning là gì” đang là chủ đề quen thuộc với những ai quan tâm đến học tăng cường và các hệ thống ra quyết định tự động. Thuật toán này giúp tác nhân học từ phần thưởng, tối ưu từng hành động và dần tìm ra chiến lược hiệu quả nhất mà không cần biết trước cấu trúc môi trường.
Việc hiểu rõ nguyên lý Q-Learning sẽ giúp người học tiếp cận những mô hình hiện đại trong nhiều lĩnh vực công nghệ.
Q-Learning là gì?
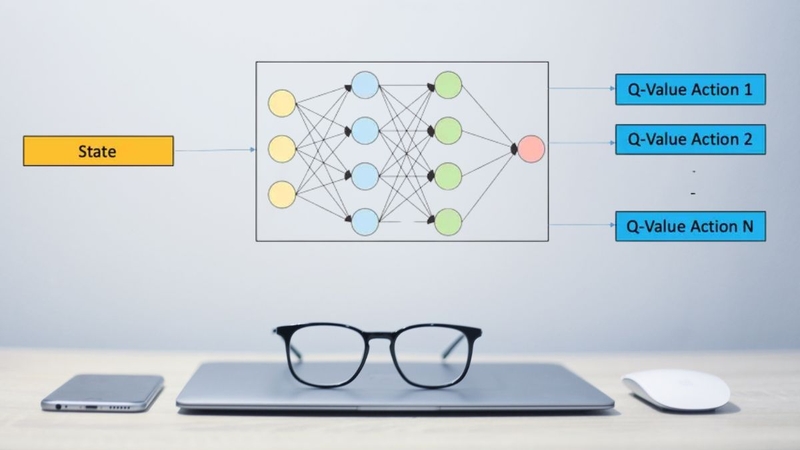
Q-Learning là một thuật toán học tăng cường cho phép tác nhân học cách thực hiện hành động tối ưu trong môi trường chưa biết trước. Thay vì dựa vào dữ liệu huấn luyện, tác nhân tự tương tác, ghi nhận phần thưởng và cập nhật giá trị để cải thiện chiến lược.
Cơ chế học dựa trên trải nghiệm
Trong Q-Learning, tác nhân quan sát trạng thái, chọn hành động và nhận phần thưởng. Từ đó, tác nhân cập nhật giá trị Q cho hành động tại trạng thái vừa xảy ra. Quá trình này lặp lại nhiều lần giúp tác nhân củng cố hành động mang lại lợi ích cao.
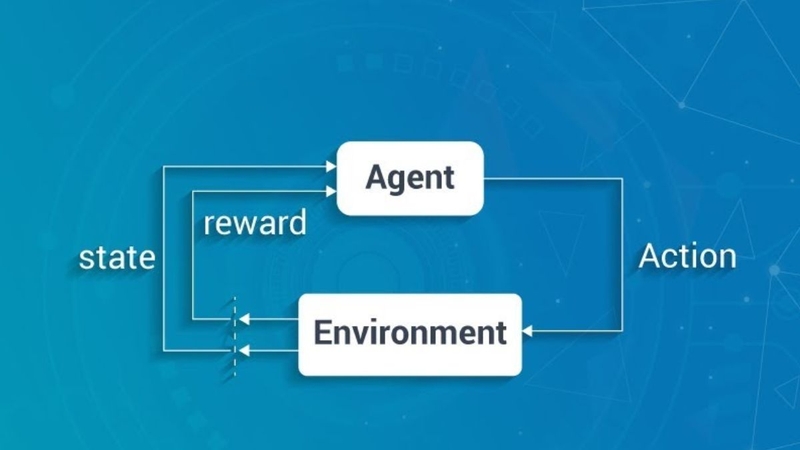
Q-Value giữ vai trò trung tâm
Q-Value là con số dự đoán mức lợi ích khi thực hiện một hành động tại một trạng thái. Mỗi hành động được đánh giá bằng giá trị Q, qua đó tác nhân xác định hành động tối ưu trong từng tình huống. Đây là nền tảng của chiến lược ra quyết định trong Q-Learning.
Các tham số quan trọng trong Q-Learning
Muốn hiểu sâu Q-Learning là gì, người học cần nắm rõ các tham số ảnh hưởng trực tiếp đến tốc độ và chất lượng quá trình học.
Learning Rate và Discount Factor
Learning Rate quyết định mức độ tác nhân tiếp thu thông tin mới. Giá trị cao giúp tác nhân học nhanh nhưng dễ nhiễu. Discount Factor thể hiện tầm quan trọng của phần thưởng tương lai so với phần thưởng tức thời. Hai tham số này tạo nên sự cân bằng giữa kinh nghiệm mới và giá trị lâu dài.
Exploration và Exploitation
Trong Q-Learning, tác nhân vừa cần khám phá môi trường vừa cần khai thác kiến thức hiện tại. Chiến lược Epsilon-Greedy được dùng để giữ sự cân bằng này. Khi Epsilon giảm dần theo thời gian, tác nhân dần ưu tiên hành động có giá trị Q cao hơn.
Phương trình Bellman trong Q-Learning
Muốn thuật toán hoạt động đúng, tác nhân phải dựa vào phương trình Bellman để cập nhật giá trị Q.
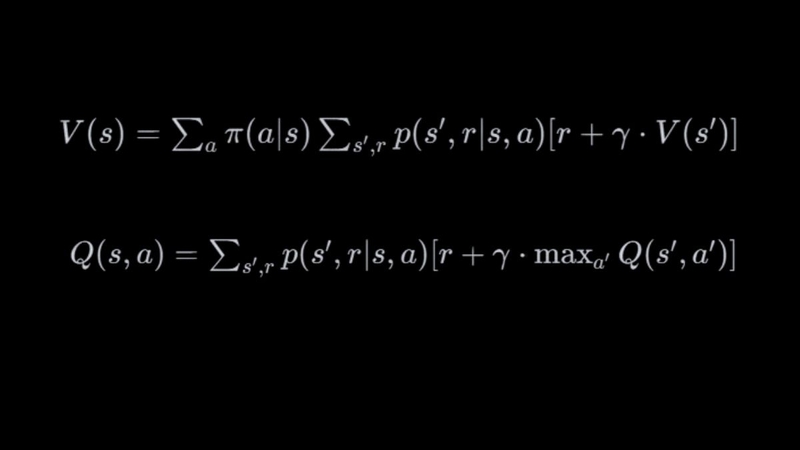
Bellman cho giá trị hành động
Phương trình Bellman mô tả giá trị hành động dựa trên phần thưởng nhận được và giá trị cao nhất của trạng thái tiếp theo. Sự kết hợp giữa phần thưởng thực tế và dự đoán tương lai giúp tác nhân học dần một chiến lược tối ưu.
Vai trò của phương trình trong quá trình cập nhật
Phương trình này giúp tác nhân biết cách điều chỉnh Q-Value mỗi khi tương tác môi trường. Nhờ đó chiến lược trở nên chính xác hơn sau mỗi vòng lặp học.
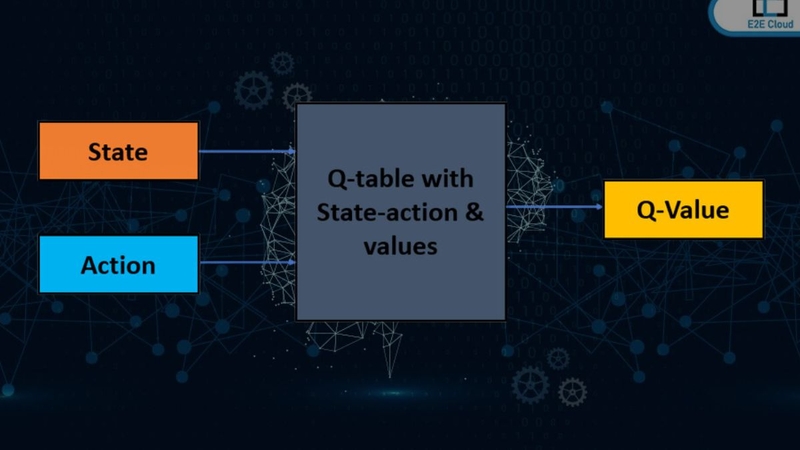
Deep Q-Learning và sự mở rộng của Q-Learning
Khi số lượng trạng thái quá lớn, bảng Q truyền thống không còn phù hợp. Deep Q-Learning sử dụng mạng nơ-ron để ước lượng giá trị hành động.
Mạng nơ-ron dự đoán Q-Value
Thay vì lưu toàn bộ Q-Value trong một bảng lớn, Deep Q-Learning huấn luyện mạng nơ-ron dự đoán giá trị cho từng trạng thái. Phương pháp này phù hợp với môi trường phức tạp, chẳng hạn như game hoặc điều khiển robot.
Bộ nhớ trải nghiệm giúp ổn định quá trình học
Deep Q-Learning dùng bộ nhớ trải nghiệm để lưu dữ liệu quá trình tương tác. Cách này giúp mô hình học từ nhiều trạng thái khác nhau và giảm ảnh hưởng của các mẫu liên tiếp, nhờ đó quá trình học ổn định và hiệu quả hơn.
Ứng dụng thực tế của Q-Learning
Khi hiểu Q-Learning là gì, người học sẽ dễ dàng thấy sự xuất hiện của thuật toán này trong nhiều lĩnh vực hiện đại.
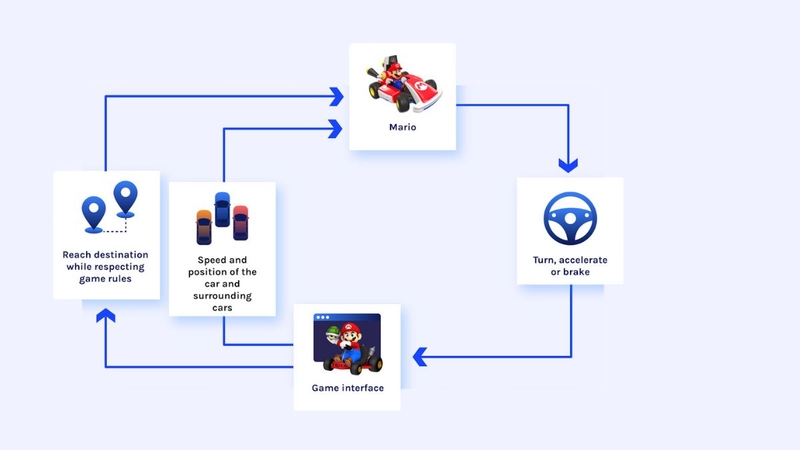
Ứng dụng trong điều khiển robot
Robot dùng Q-Learning để học cách di chuyển và tránh vật cản. Tác nhân quan sát môi trường, thử nhiều hành động và điều chỉnh chiến lược để đạt hiệu quả cao hơn.
Ứng dụng trong game và mô phỏng
Các trò chơi yêu cầu tác nhân đưa ra nhiều quyết định liên tục. Q-Learning giúp mô hình tìm đường đi, đối phó chiến thuật hoặc tối ưu điểm số.
Tối ưu hóa tài nguyên và vận hành hệ thống
Trong các hệ thống mạng hoặc phân phối tài nguyên, Q-Learning hỗ trợ tìm chiến lược tối ưu nhằm giảm chi phí và tăng hiệu quả hoạt động.
Ví dụ trực quan về Q-Learning trong mô hình lưới
Để hiểu rõ hơn Q-Learning là gì, người học có thể hình dung môi trường lưới với tác nhân di chuyển từ điểm đầu đến điểm đích.
Tác nhân tương tác trong môi trường đơn giản
Tác nhân bắt đầu từ vị trí cố định và chọn các bước di chuyển dựa trên bảng Q. Khi gặp vùng có thưởng, giá trị Q tăng; khi gặp vùng phạt, giá trị Q giảm. Quá trình này tạo nên phản xạ tối ưu cho tác nhân.
Chiến lược dần hoàn thiện theo thời gian
Sau nhiều vòng học, tác nhân lựa chọn những hành động mang lại tổng thưởng cao. Nhờ vậy tác nhân tìm được đường đi tối ưu trong mô hình lưới.
Tạm kết
Qua đây, bạn đã hiểu được Q-Learning là gì. Đây là nền tảng cho nhiều mô hình ra quyết định tự động trong trí tuệ nhân tạo. Khi hiểu rõ cơ chế cập nhật giá trị và ứng dụng thực tế, người học có thể tiếp cận sâu hơn vào lĩnh vực học tăng cường.
Bạn hãy khám phá các laptop AI tại FPT Shop để hỗ trợ học thuật toán Q-Learning, chạy mô hình hiệu quả và nâng cao trải nghiệm nghiên cứu AI nhé.
Xem thêm:
:quality(75)/giai_thua_la_gi_cover_c545534d3b.png)
:quality(75)/jetstream_0_cd9f25acee.png)
:quality(75)/mang_2_chieu_0_69b82f2fc6.jpg)
:quality(75)/constraint_la_gi_0_e5175e1839.jpg)
:quality(75)/codekitten_67042afe0b.jpg)
:quality(75)/phan_mem_lap_trinh_cho_hoc_sinh_0_1_1_38e192a0aa.jpg)