:quality(75)/2023_11_29_638368940142205601_hadoop-la-gi.jpg)
Hadoop là gì? Tất tần tật các thông tin về công cụ phân tích hiệu quả cho Big Data
Trong loạt công cụ dành cho việc xử lý Big Data, Hadoop nổi bật như một giải pháp hiệu quả và mạnh mẽ. Hadoop không chỉ giúp giải quyết vấn đề của lượng dữ liệu lớn, mà còn mang lại khả năng dự đoán và phân tích sâu rộng. Nó không chỉ là một công cụ thông thường, mà còn là một hệ sinh thái đầy đủ, đáp ứng được nhu cầu ngày càng cao của ngành công nghiệp xử lý và khai thác Big Data. Vậy nên, để hiểu rõ Hadoop là gì? Cách Hadoop hoạt động và đóng góp của nó trong lĩnh vực Big Data, hãy cùng tìm hiểu trong bài viết dưới đây.

Apache Hadoop là gì?
Apache Hadoop là gì? Đây không chỉ là một framework mà còn là một dự án mã nguồn mở quan trọng, cho phép việc quản lý và lưu trữ dữ liệu lớn thông qua phương pháp xử lý phân tán. Điểm đặc biệt của Hadoop chính là sự tích hợp mô hình MapReduce vào quá trình xử lý dữ liệu lớn.
MapReduce, xuất phát từ Google, chịu trách nhiệm xử lý khối lượng lớn dữ liệu. Nó tiếp nhận dữ liệu lớn và chia thành các đơn vị nhỏ, sau đó sắp xếp và trích xuất dữ liệu phù hợp với yêu cầu người dùng. Mô hình này là cơ sở cho cách Google Search hoạt động hàng ngày.
Hadoop sử dụng MapReduce như một nền tảng lý tưởng, giúp người dùng tổng hợp và xử lý lượng thông tin lớn trong khoảng thời gian ngắn.

Đối với chức năng lưu trữ, Hadoop sử dụng HDFS (Hadoop Distributed File System). HDFS được thiết kế để có độ truy cập nhạy và chi phí thấp, tạo ra một kho thông tin linh hoạt và hiệu quả.
Hadoop ban đầu được phát triển bằng ngôn ngữ Java, nhưng nó cũng hỗ trợ nhiều ngôn ngữ lập trình khác như C++, Python, hoặc Pearl thông qua cơ chế streaming. Điều này tạo ra sự linh hoạt cho người phát triển sử dụng nền tảng này.
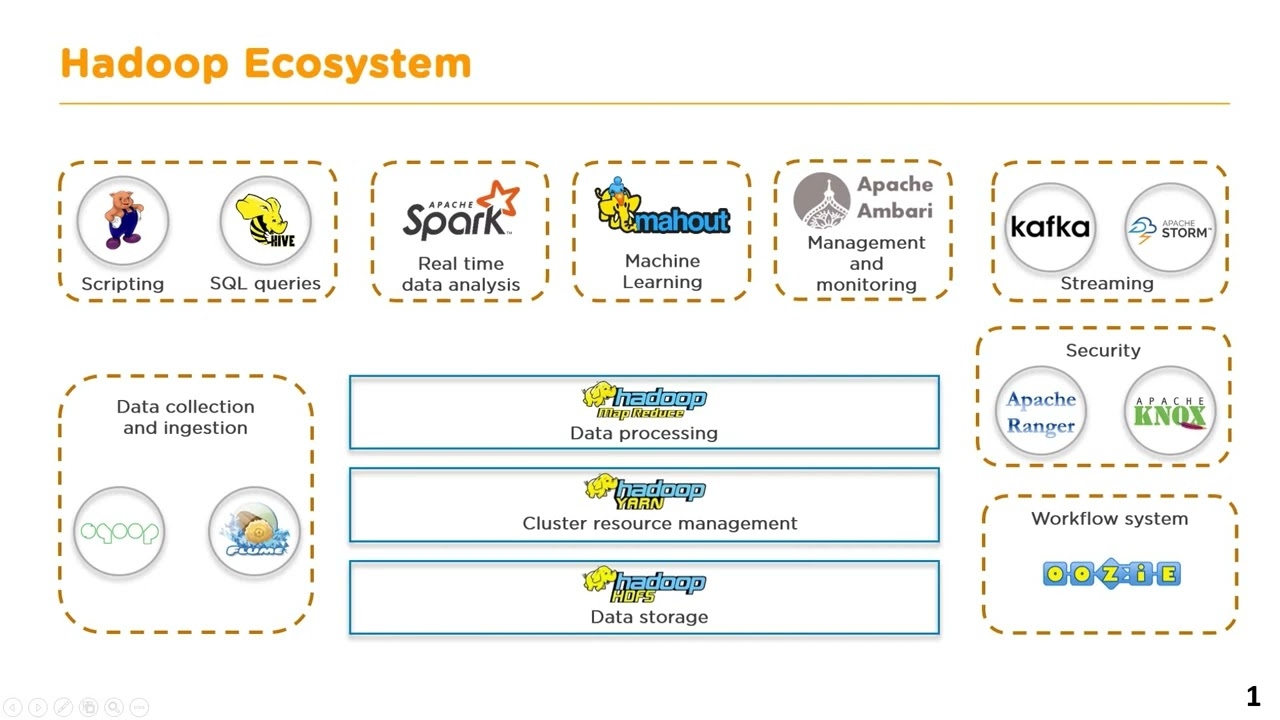
Apache Hadoop có các đặc điểm nổi bật như sự tích hợp MapReduce, HDFS hiệu quả và khả năng hỗ trợ nhiều ngôn ngữ, đã trở thành một công cụ mạnh mẽ trong việc xử lý và quản lý dữ liệu lớn, đồng thời mang lại hiệu suất và linh hoạt đáng kể cho người sử dụng.
Cách thành phần của Apache Hadoop
Cách thành phần của Apache Hadoop là một hợp nhất giữa cấu trúc MapReduce và Hadoop Distributed File System (HDFS). Điều này giúp Hadoop kế thừa những đặc điểm quan trọng từ cả hai phần.

Một cụm Hadoop bao gồm một master node (node chủ) và nhiều worker/slave node (node nhân viên). Cụm này được chia thành hai lớp chính: MapReduce layer và HDFS layer. Master node có các thành phần quan trọng như JobTracker, TaskTracker, NameNode, và DataNode. Trong khi đó, Worker/Slave node chứa DataNode và TaskTracker, có thể sử dụng cho việc xử lý dữ liệu hoặc tính toán tùy thuộc từng yêu cầu cụ thể.
Apache Hadoop bao gồm 4 module chính, và dưới đây là giới thiệu chi tiết về từng loại:
Hadoop Common
Hadoop Common hoạt động như một thư viện lưu trữ các tiện ích của Java, cung cấp các tính năng cần thiết cho các modules khác. Thư viện này bao gồm hệ thống file và lớp OS trừu tượng. Ngoài ra, nó cũng chứa mã lệnh Java cần thiết để khởi động Hadoop.
Hadoop YARN
Hadoop YARN (Yet Another Resource Negotiator) hoạt động như một framework hỗ trợ quản lý thư viện tài nguyên trong các cluster và thực hiện chạy các tiến trình phân tích. Điều này cung cấp sự linh hoạt cho việc phân phối và sử dụng nguồn lực, giúp tối ưu hóa hiệu suất của hệ thống.

Hadoop Distributed File System (HDFS)
Một trong những thách thức lớn của hệ thống phân tích Big Data là khả năng chịu tải. Không phải mọi hệ thống đều có khả năng xử lý lượng dữ liệu lớn một cách hiệu quả. Chính vì vậy, Hadoop Distributed File System (HDFS) ra đời với mục tiêu chính là phân tán và cung cấp khả năng truy cập thông lượng cao cho các ứng dụng chủ.
Khi HDFS nhận được một tệp tin, nó tự động chia file thành nhiều phần nhỏ. Những phần nhỏ này được nhân bản và phân tán lưu trữ trên nhiều máy chủ, giảm áp lực và tăng hiệu suất hệ thống. Cấu trúc của HDFS bao gồm master node và worker/slave node. Master node quản lý metadata của các file, trong khi worker/slave node (còn gọi là data node) chịu trách nhiệm lưu trữ dữ liệu.
Data node chứa nhiều khối dữ liệu nhỏ của tệp tin và dưới sự chỉ đạo của master node, chúng thực hiện các thao tác thêm, xóa dữ liệu nhằm duy trì cân bằng tải và tối ưu hóa hiệu suất hệ thống. HDFS giúp giải quyết một trong những thách thức lớn nhất của việc xử lý Big Data - quản lý dữ liệu lớn một cách hiệu quả.
Hadoop MapReduce
Hadoop MapReduce là một module hoạt động dựa trên YARN, đóng vai trò quan trọng trong việc xử lý các tệp dữ liệu lớn. Module này cho phép phân tán dữ liệu từ máy chủ chính sang nhiều máy con khác nhau. Mỗi máy con nhận một phần dữ liệu, đồng thời thực hiện xử lý độc lập. Kết quả sau cùng được báo cáo và tổng hợp lại trên máy chủ.

Quá trình thực thi theo mô hình này mang lại nhiều lợi ích, như giảm thời gian xử lý và giảm áp lực cho hệ thống. Máy chủ chịu trách nhiệm quản lý tài nguyên, cung cấp thông báo và lập lịch hoạt động cho các máy con. Các máy con thực hiện các nhiệm vụ theo lịch trình được xác định trước và báo cáo kết quả về máy chủ.
Tuy nhiên, một điểm yếu của hệ thống là nếu máy chủ gặp sự cố, toàn bộ quá trình xử lý có thể bị tạm dừng. Điều này đòi hỏi sự ổn định và bảo trì đặc biệt để đảm bảo tính liên tục của hệ thống.
Cách Hadoop hoạt động
Hoạt động của Hadoop là gì? Hadoop hoạt động theo mô hình MapReduce, được thực hiện qua một loạt các giai đoạn cụ thể sau:
Giai đoạn 1: Yêu cầu xử lý người dùng hoặc ứng dụng gửi một job lên Hadoop để yêu cầu xử lý dữ liệu. Job này chứa các thông tin cơ bản như nơi lưu trữ dữ liệu input và output, các class Java chứa lệnh thực thi và các thiết lập cụ thể.
Giai đoạn 2: Phân phối công việc máy chủ, chia khối lượng công việc cho các máy trạm theo thông tin từ job. Nó theo dõi quá trình hoạt động của các máy trạm và thực hiện các lệnh quản lý khi có sự cố xảy ra.
Giai đoạn 3: Thực hiện MapReduce, các nodes thực hiện tác vụ MapReduce bằng cách chia nhỏ dữ liệu và xử lý nó một cách đồng thời. Trong quá trình hoạt động, Hadoop sử dụng một tệp tin nền làm địa chỉ thường trú. Tệp tin này có thể được phân tán trên một hoặc nhiều máy chủ khác nhau, tùy thuộc vào yêu cầu xử lý cụ thể.
Ưu điểm của Hadoop
Ưu điểm của Hadoop là gì? Chúng ta cùng tìm hiểu các ưu điểm của nó khi xử lý dữ liệu lớn:
- Xử lý nhanh chóng và liên tục: Hadoop cho phép kiểm tra tiến trình hoạt động của các phần phân tán một cách nhanh chóng. Nhờ cơ chế xử lý đồng thời các lõi CPU, dữ liệu lớn được phân phối liên tục mà không gặp sự gián đoạn do quá tải.
- Khả năng chịu lỗi cao: Hadoop không bị ảnh hưởng bởi cơ chế chịu lỗi (fault-tolerance and high availability - FTHA). Các thư viện được thiết kế để phát hiện lỗi ở các lớp ứng dụng, giúp Hadoop xử lý lỗi nhanh chóng và hiệu quả khi chúng xảy ra.
- Triển khai đa nền tảng: Khả năng triển khai nhiều master-slave song song của Hadoop cho phép xử lý các phần khác nhau mà không làm trễ công việc, ngay cả khi một master gặp sự cố.
- Tương thích các nền tảng: Do được xây dựng từ ngôn ngữ Java, Hadoop tương thích với nhiều nền tảng và hệ điều hành khác nhau, bao gồm Windows, Linux, và MacOS.
Kết luận
Với đầy đủ thông tin từ định nghĩa, đặc điểm đến cách thức hoạt động, Hadoop là một công cụ mạnh mẽ để xử lý dữ liệu lớn. Việc nắm vững kiến thức này sẽ giúp bạn áp dụng Hadoop một cách hiệu quả trong công việc của mình. Hy vọng với các thông tin trên, bạn đã hiểu Hadoop là gì và các thông tin liên quan về nó. Chúc bạn học hỏi thành công và sử dụng ứng dụng Hadoop một cách thành thạo!
Xem thêm:
- Tìm hiểu ngôn ngữ lập trình C và hướng dẫn cách tự học dành cho người mới bắt đầu
- Top 10 phần mềm lập trình tốt nhất cho Windows năm 2023 mà mọi Coder không nên bỏ qua
Nếu bạn muốn mua một laptop lập trình tốt, hãy đến ngay FPT Shop để nhận tư vấn các mẫu laptop chính hãng, giá thành ưu đãi.
Xem ngay các laptop cấu hình cao tại đây: Laptop cao cấp
:quality(75)/2023_11_26_638365957450396249_docker-la-gi-bia.jpg)
:quality(75)/2023_11_12_638354079338197220_cach-lap-trinh-game-11.jpg)
:quality(75)/2023_11_22_638362866156047222_crud-la-gi-1-1.jpg)
:quality(75)/2023_11_24_638364653950314747_microsevives-1-1.jpg)
:quality(75)/2023_11_26_638366330013709188_scala-la-gi-2.jpg)
:quality(75)/2023_11_10_638351762439910029_game-lap-trinh.jpg)