:quality(75)/2024_2_7_638429025249905743_hbase-1-1.jpg)
Hbase là gì? Mách bạn cách cài đặt và tận dụng những tính năng đặc biệt của Hbase
Hbase đã trở thành một trong những giải pháp lưu trữ dữ liệu lớn (Big Data). Nền tảng được các tập đoàn công nghệ hàng đầu ứng dụng liên tục trong thời gian dài. Vậy những tính năng đặc biệt của Hbase là gì? Cách sử dụng loại Big Data này như thế nào? Mời bạn theo dõi bài viết được FPT Shop bật mí để tìm ra đáp án cần biết!
Giới thiệu những kiến thức cơ bản về Hbase
HBase là hệ thống cơ sở dữ liệu được xây dựng trên cơ sở Apache Hadoop. Công nghệ được thiết kế để lưu trữ và xử lý lượng lớn dữ liệu cấu trúc, bán cấu trúc trên các cụm máy chủ phân tán. Hệ thống này cung cấp khả năng lưu trữ dữ liệu tập trung và phân phối nhanh chóng. Kèm theo đó là khả năng mở rộng linh hoạt để đáp ứng nhu cầu về gia tăng dữ liệu trong những trường hợp cần thiết.

HBase sử dụng kiến trúc cột dựa trên Google Bigtable, nơi dữ liệu được tổ chức theo các hàng và cột. Nền tảng cũng cung cấp khả năng truy xuất dữ liệu theo hàng hoặc phạm vi các cột, đồng thời hỗ trợ việc mở rộng tập tin và tìm kiếm nhanh chóng.
HBase thường được sử dụng trong các ứng dụng yêu cầu lưu trữ dữ liệu lớn và việc truy xuất dữ liệu với độ trễ thấp. Các trường hợp sử dụng phổ biến của HBase bao gồm lưu trữ log, dữ liệu kết hợp và các ứng dụng web có lượng truy cập lớn.
Những tính năng chính của Hbase
HBase có nhiều tính năng mạnh mẽ giúp nó phục vụ việc lưu trữ và truy xuất cấu trúc dữ liệu và bán cấu trúc trong môi trường phân tán. Dưới đây là một vài tiện ích nổi bật của công cụ mà bạn nên biết:

- Lưu trữ dữ liệu phân tán: HBase sử dụng kiến trúc phân tán để lưu trữ dữ liệu trên nhiều máy chủ, cho phép nó lưu trữ và xử lý lượng dữ liệu lớn.
- Hàng và cột cung cấp mô hình dữ liệu linh hoạt: Dữ liệu được tổ chức trong HBase theo hàng và cột, giúp việc truy xuất dữ liệu hiệu quả và cung cấp tính linh hoạt khi cần thay đổi cấu trúc dữ liệu.
- Hỗ trợ truy vấn phạm vi cột và hàng: HBase cho phép truy vấn dựa trên các phạm vi cột hoặc hàng, cung cấp khả năng truy xuất dữ liệu một cách hiệu quả.
- Mở rộng linh hoạt: HBase có khả năng mở rộng tập tin và dữ liệu một cách linh hoạt, giúp nó thích hợp cho việc xử lý lượng dữ liệu tăng nhanh.
- Độ trễ thấp: HBase cung cấp hiệu suất truy xuất dữ liệu với độ trễ thấp, phù hợp cho các ứng dụng yêu cầu truy xuất dữ liệu nhanh.
- Hỗ trợ ghi và đọc dữ liệu đa nhóm (multi versioning): HBase hỗ trợ việc lưu trữ nhiều phiên bản của dữ liệu, cho phép truy xuất các phiên bản dữ liệu khác nhau.
- Tích hợp với Hadoop ecosystem: HBase được tích hợp tốt với hệ sinh thái Hadoop, cho phép tích hợp dễ dàng với các công cụ và framework khác trong hệ sinh thái này.
Khám phá mô hình cơ bản của Hbase
Data Model
Mô hình dữ liệu của HBase được xây dựng dựa trên kiến trúc cột (Column-oriented) và có tính linh hoạt cao, phù hợp với việc lưu trữ và truy xuất dữ liệu cấu trúc và bán cấu trúc trong môi trường phân tán. Dưới đây giới thiệu chi tiết về mô hình dữ liệu của HBase:
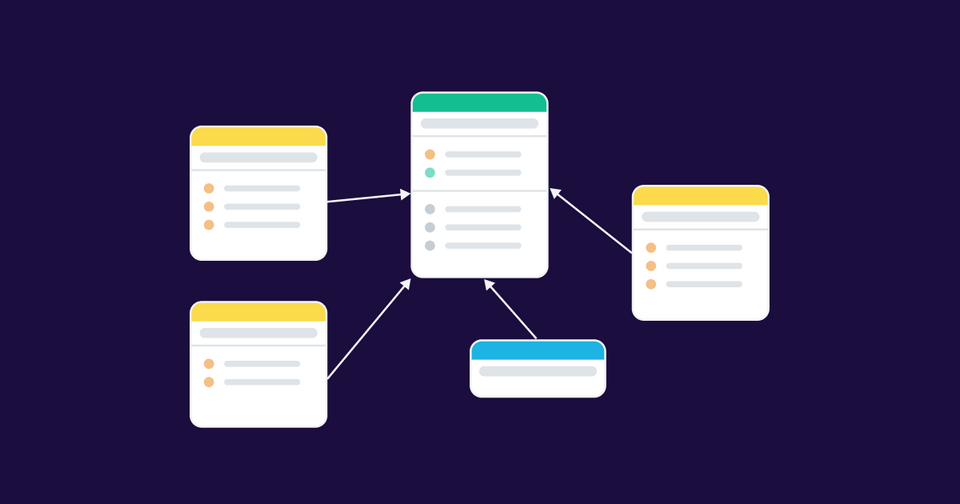
- Bảng (Table): Trong HBase, dữ liệu được tổ chức thành các bảng. Mỗi bảng chứa nhiều hàng và cột tương ứng với dữ liệu được lưu trữ. Mỗi bảng được định nghĩa bởi tên bảng duy nhất.
- Hàng (Row): Mỗi hàng trong HBase được xác định bằng một khóa chính duy nhất. Hàng được sắp xếp theo thứ tự tại cấp độ lưu trữ, giúp tối ưu việc truy xuất dữ liệu dựa trên khóa.
- Cột (Column): Dữ liệu là một danh sách các cặp "tên cột - giá trị" đồng thời không cần phải định nghĩa trước. HBase cho phép mở rộng linh hoạt khi cần thêm cột mà không cần sự can thiệp vào cấu trúc tổ chức dữ liệu.
- Gia đình cột (Column Family): Các cột được tổ chức thành các gia đình cột, mỗi gia đình cột bao gồm một hoặc nhiều cột. Mỗi hàng trong bảng có thể chứa nhiều gia đình cột, giúp tối ưu hóa lưu trữ dữ liệu theo logic và cải thiện hiệu suất truy xuất.
- Phiên bản của ô dữ liệu (Cell Versioning): HBase hỗ trợ lưu trữ nhiều phiên bản của ô dữ liệu, cho phép truy xuất các phiên bản dữ liệu khác nhau theo thời gian, giúp theo dõi sự thay đổi của dữ liệu.
- Khóa dữ liệu (Data Key): Mỗi ô dữ liệu được xác định bởi một khóa dữ liệu (Data Key) độc nhất. Khóa dữ liệu bao gồm tên bảng, khóa hàng, tên gia đình cột và tên cột, giúp xác định một cách duy nhất mỗi ô dữ liệu trong bảng.
Mô hình dữ liệu của HBase được thiết kế để giải quyết các vấn đề liên quan đến lưu trữ và truy xuất dữ liệu lớn trong môi trường phân tán ứng dụng Big Data. Cách thiết kế dựa trên các đặc tính này đã giúp cho HBase trở thành một trong những giải pháp quan trọng cho các ứng dụng yêu cầu xử lý lượng dữ liệu lớn với hiệu suất cao.
Auto Sharding
Auto Sharding là một phương pháp quan trọng trong việc tự động phân chia và phân phối dữ liệu trên các nút (node) máy chủ trong một hệ thống cơ sở dữ liệu phân tán. Trong quá trình hoạt động cùng HBase, Auto Sharding có những đặc điểm nổi bật sau đây:
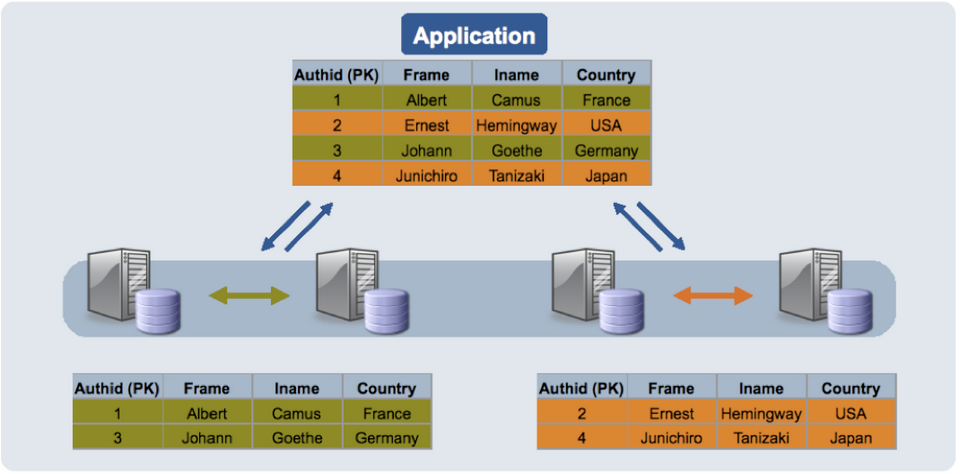
- Phân chia dữ liệu tự động: Khi dữ liệu được thêm vào HBase, hệ thống sẽ tự động phân chia và phân bố dữ liệu trên nhiều máy chủ trong cụm dựa trên khóa chính (Primary key). Quá trình này giúp giảm tải cho mỗi máy chủ và tăng khả năng mở rộng (Scalability) của hệ thống.
- Cân bằng tải (Load Balancing): Auto Sharding giúp phân phối công việc đồng đều trên các nút máy chủ trong cụm, tránh tình trạng quá tải hoặc ít hoạt động. Điều này đảm bảo rằng mỗi máy chủ nhận được lượng công việc tương đối đồng đều, tối ưu hóa hiệu suất của hệ thống.
- Mở rộng linh hoạt: Khi lượng dữ liệu tăng lên, Auto Sharding cho phép hệ thống dễ dàng mở rộng bằng cách thêm máy chủ vào cụm mà không gây ra sự cố hoặc gián đoạn hoạt động của hệ thống, do dữ liệu được phân phối đều.
- Tính khả dụng cao (High Availability): Auto Sharding cũng cung cấp tính năng sao lưu và tự động sao chép dữ liệu trên các nút máy chủ khác nhau, tạo ra tính dự phòng và tăng tính khả dụng của hệ thống.
Nhìn chung, Auto Sharding giúp HBase và các hệ thống cơ sở dữ liệu phân tán khác có khả năng lưu trữ và xử lý dữ liệu lớn một cách hiệu quả. Đồng thời, công nghệ có tác dụng tối ưu hóa hiệu suất và tính khả dụng trong môi trường phân tán.
Vài điều cần biết về kiến trúc HBase
Kiến trúc của HBase bao gồm các yếu tố cơ bản sau:
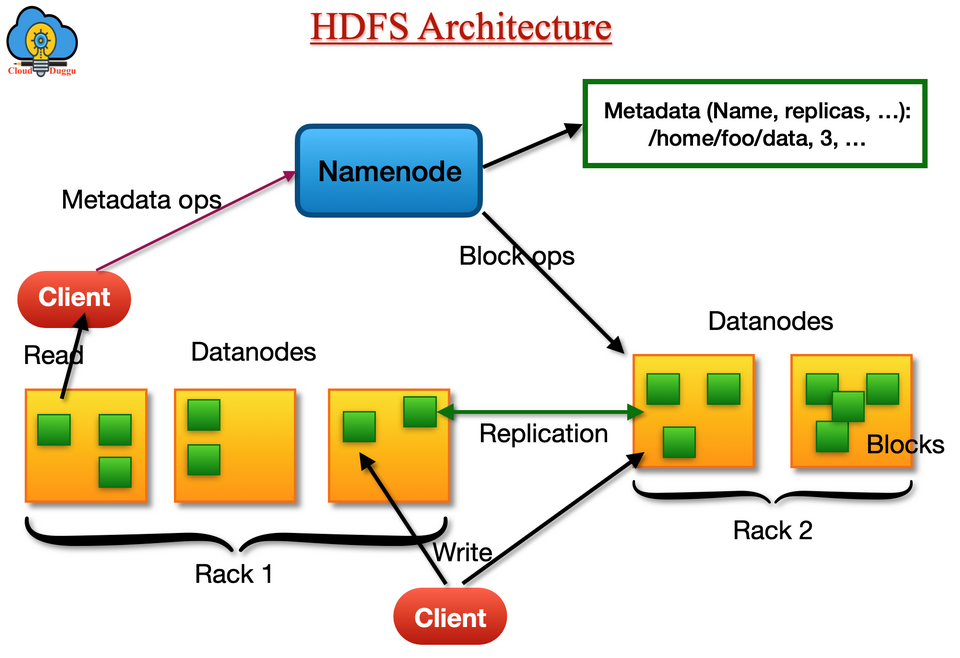
Hadoop HDFS
HBase sử dụng Hadoop Distributed File System (HDFS) làm hệ thống lưu trữ dữ liệu cơ bản. HBase lưu trữ dữ liệu trên HDFS dưới dạng các file HFile và sử dụng sự phân tán và đệ quy của HDFS để quản lý dữ liệu.
ZooKeeper
HBase sử dụng ZooKeeper để quản lý Metadata và dịch vụ phân tán. ZooKeeper giúp trong việc quản lý và đồng bộ hóa các máy chủ HBase, theo dõi trạng thái của cụm và cung cấp các dịch vụ phân tán khác.
HRegionServer
HBase sử dụng HRegionServer để lưu trữ và xử lý dữ liệu. Mỗi bảng trong HBase được chia thành nhiều phần nhỏ gọi là Region và mỗi Region được giao cho một HRegionServer xử lý.

HMaster
HMaster quản lý cụm HBase và điều phối các hoạt động của các HRegionServer. HMaster chịu trách nhiệm trong việc quản lý siêu dữ liệu (Metadata) của HBase, quản lý tạo, xóa, điều chỉnh Regions và phục hồi từ trạng thái lỗi.
Apache HBase Client
Đây là giao diện mà các ứng dụng client sử dụng để tương tác với cụm HBase. Apache HBase Client cung cấp các phương thức để đọc, viết và xóa dữ liệu từ HBase.
HBase Cluster
Cụm HBase là tập hợp các máy chủ HBase, bao gồm HMaster và HRegionServer để cung cấp dịch vụ lưu trữ và truy xuất dữ liệu phân tán.
Theo dõi các thành phần trong kiến trúc HBase sẽ cho ta thấy cái nhìn tổng quan về cách HBase sử dụng HDFS, ZooKeeper và các thành phần nội tại của nó. Từ đó, hệ thống sẽ cung cấp môi trường lưu trữ và truy xuất dữ liệu phân tán, hỗ trợ tính mở rộng và khả năng tính toán lớn.
Bí quyết tận dụng HBase đạt kết quả tốt nhất

Để sử dụng HBase một cách hiệu quả và có kết quả tốt nhất, bạn cần xem xét các điểm sau:
- Thiết kế bảng chặt chẽ: Hãy xác định cụ thể cách mà dữ liệu sẽ được truy cập và sử dụng và thiết kế bảng dựa trên nhu cầu truy xuất của ứng dụng. Cân nhắc việc sử dụng gia đình cột (Column family) sao cho phù hợp với mô hình dữ liệu và mẫu truy xuất của bạn.
- Tối ưu hóa schema: Tối ưu hóa cấu trúc bảng để phản ánh mẫu truy xuất dữ liệu. Để giảm Overhead của bảng và tăng hiệu suất truy xuất thì người dùng nên hạn chế việc triển khai quá nhiều cột hoặc áp dụng chế độ gia đình cột (Column family).
- Xác định khóa chính (Primary Key) hợp lý: Lựa chọn khóa chính để phân phối dữ liệu một cách đồng đều trên các nút (nodes) HBase, tránh tình trạng "hotspotting" mà một số nút phải xử lý lượng dữ liệu lớn hơn.
- Tối ưu hóa truy xuất dữ liệu: Sử dụng index thứ cấp, filter và cắt dữ liệu (Data pruning) để tối ưu hóa truy xuất dữ liệu, giảm tải cho HBase và tăng hiệu suất truy vấn.
- Xử lý tải lớn và hiệu suất: Xác định và cấu hình tùy chọn hiệu suất như Cache, bộ nhớ đệ quy và tùy chọn ghi đồng thời (Write - ahead logging) để đảm bảo hiệu suất khi xử lý tải lớn.
- Quản lý độ trễ và tính khả dụng trong quản lý: Đánh giá và tối ưu hóa các cài đặt liên quan đến độ trễ và tính khả dụng, bao gồm cấu hình ZooKeeper, cấu hình sao lưu và khôi phục và quản lý các sự cố và trạng thái lỗi.
Tạm kết
Qua đây, FPT Shop hy vọng bạn đọc đã cập nhật được nhiều kiến thức hữu ích về HBase. Điều này chắc chắn sẽ giúp bạn xử lý công việc trong ngành lưu trữ và truy cập dữ liệu hiệu quả.
Xem thêm:
- WAF là gì? Bật mí những ứng dụng đặc biệt của tường lửa đối với Doanh nghiệp
- Imunify360 là gì? Những cách bảo vệ Hosting Linux hiệu quả mà không phải ai cũng biết
Tại FPT Shop cung cấp nhiều loại máy tính bảng và laptop có cấu hình cao. Cửa hàng luôn cập nhật nhiều dòng máy đời mới để đáp ứng nhu cầu của khách hàng yêu thích công nghệ. Bạn hãy ghé thăm cửa hàng để lựa chọn những sản phẩm chất lượng nhé!
:quality(75)/2023_11_18_638359209913644361_sonarqube-la-gi-1-1.png)
:quality(75)/2024_1_13_638407799876276739_redis-la-gi-1-1.jpg)
:quality(75)/2023_12_24_638390208217265438_open-stack.jpg)
:quality(75)/2024_1_3_638398866132368464_anh-dai-dien.jpg)
:quality(75)/2023_8_30_638290179367758057_luu-du-lieu-camera-tren-icloud.jpg)